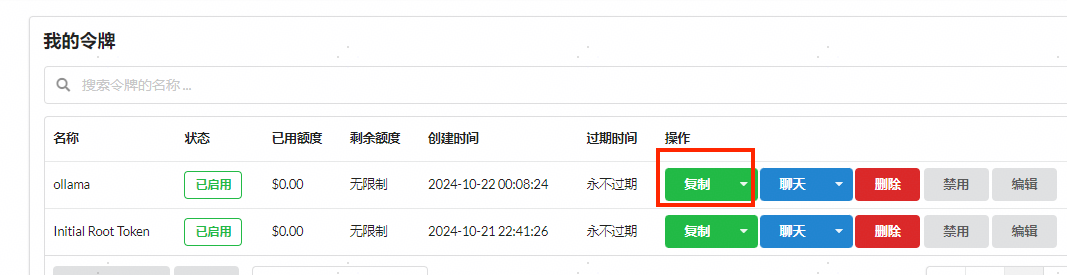
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| llmModels
{
"model": "qwen2.5:7b", // 模型名(对应OneAPI中渠道的模型名)
"name": "qwen2.5:7b", // 模型别名
"avatar": "/imgs/model/openai.svg", // 模型的logo
"maxContext": 125000, // 最大上下文
"maxResponse": 16000, // 最大回复
"quoteMaxToken": 120000, // 最大引用内容
"maxTemperature": 1.2, // 最大温度
"charsPointsPrice": 0, // n积分/1k token(商业版)
"censor": false, // 是否开启敏感校验(商业版)
"vision": true, // 是否支持图片输入
"datasetProcess": true, // 是否设置为文本理解模型(QA),务必保证至少有一个为true,否则知识库会报错
"usedInClassify": true, // 是否用于问题分类(务必保证至少有一个为true)
"usedInExtractFields": true, // 是否用于内容提取(务必保证至少有一个为true)
"usedInToolCall": true, // 是否用于工具调用(务必保证至少有一个为true)
"usedInQueryExtension": true, // 是否用于问题优化(务必保证至少有一个为true)
"toolChoice": true, // 是否支持工具选择(分类,内容提取,工具调用会用到。目前只有gpt支持)
"functionCall": false, // 是否支持函数调用(分类,内容提取,工具调用会用到。会优先使用 toolChoice,如果为false,则使用 functionCall,如果仍为 false,则使用提示词模式)
"customCQPrompt": "", // 自定义文本分类提示词(不支持工具和函数调用的模型
"customExtractPrompt": "", // 自定义内容提取提示词
"defaultSystemChatPrompt": "", // 对话默认携带的系统提示词
"defaultConfig": {}, // 请求API时,挟带一些默认配置(比如 GLM4 的 top_p)
"fieldMap": {} // 字段映射(o1 模型需要把 max_tokens 映射为 max_completion_tokens)
},
vectorModels
{
"model": "m3e", // 模型名(与OneAPI对应)
"name": "M3E", // 模型展示名
"avatar": "/imgs/model/openai.svg", // logo
"charsPointsPrice": 0, // n积分/1k token
"defaultToken": 700, // 默认文本分割时候的 token
"maxToken": 3000, // 最大 token
"weight": 100, // 优先训练权重
"defaultConfig":{}, // 自定义额外参数。例如,如果希望使用 embedding3-large 的话,可以传入 dimensions:1024,来返回1024维度的向量。(目前必须小于1536维度)
"dbConfig": {}, // 存储时的额外参数(非对称向量模型时候需要用到)
"queryConfig": {} // 参训时的额外参数
}
|